How do you measure ability
What e2i means by learning smart and learning fast
“We are spoiled by choices, there are simply too many resources to refer”.
While book publishing is a long and tedious process, requiring years of experience it is not the case with publishing documents on internet. Hence nowadays if you search any topic on google you get millions of resources/references. It is a connected world, and you can access research and initiatives happening in any part of the world. Also fueled by the competition, the numbers of books on a topic have increased greatly. While it is good to some extent, at the same time, it is also creating a huge amount of confusion amongst students. Some seemingly simple questions asked by students are:
· How much should I know to achieve my goal?
· How much of practice is enough?
· There will always be something that I do not know.
· How much time do I need to spend each day on studies?
· What about my leisure time?
· And many more . . . ?
Try to compare two books on the same subject/topic deeply. You will find that most of the content in these two books are similar and more than 70% of the questions are of same difficulty level (here we are mainly referring to books on the topics of science and mathematics of secondary and senior secondary level). Now, to score good a student must finish studying/practicing both the books. In this process 70% of the time and effort spent by a student is a repeat, without having any substantial benefits. It is only those 30% of the remaining study content which adds to his knowledge. Some may say “Practice makes one perfect” which is true to the last word of it. However, it doesn’t make sense to practice something which is already perfect. Let’s come back to the question, how to avoid repetition and still gain the required knowledge to achieve the set goal?
At e2i, we do research on every question to find information it can provide about the test taker. Every question information function is developed by an iterative process of solving complex statistical formulas and every question is mapped to learning objective. Thus, every time when a student takes a test and attempts a question the smart software at the backend maps his ability. Other questions requiring the initial ability to solve is omitted and the next question is presented based on the newly mapped ability. The process is iterated till the time the system reaches an error percentage of 1%. The student is then presented with his ability score and true score. Both, the scores can then be judged to check whether the student will be able to achieve his/her goal or how far he/she is. The process avoids any repetition but still gives enough practice to the student. The process also identifies strong and weak areas based on the learning objective. Students can learn smart by avoiding duplication and thus learn fast.

Theories and approaches behind e2i recommendations
“IRT is often regarded as superior to classical test theory, it is the preferred method for developing scales in the United States especially when optimal decisions are demanded, as in so-called high-stakes tests, e.g., the Graduate Record Examination (GRE) and Graduate Management Admission Test (GMAT)”.
Let’s go back to the time of having a personal teacher. A personal teacher would look at you, understand that you are facing difficulty in solving the question. He will then explain you the basic concept and then solve the problem with the help of the basic concept. We at e2i do the same. But then how do we understand that the student is facing a problem? We address this challenge using advanced models of student ability mapping. These technologies and models ensure that every student progresses through the course material in a way that maximizes his learning. Here’s a quick look at the theory and approach behind the e2i recommendation engine:
Item Response Theory (IRT)
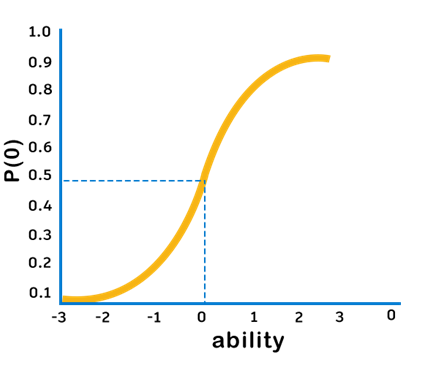
Imagine that you’re teaching mathematics to 9th graders. You’ve just administered a test with 10 questions. Of those 10 questions, two questions are very simple, two are incredibly hard, and the rest are of medium difficulty. Now imagine that two of your students take this test. Both answer nine of the 10 questions correctly. The first student answers an easy question incorrectly, while the second answers a hard question incorrectly. Which student has demonstrated greater mastery of the material? Under a traditional grading approach, you would assign both students a score of 90 out of 100 and move on to the next test. But this approach illustrates a key problem with measuring student’s ability via testing instruments: test questions do not have uniform characteristics. So how can we measure the student’s ability while accounting for differences in questions? IRT models students’ ability using question level performance instead of aggregate test level performance. Instead of assuming that all questions contribute equivalently to our understanding of a student’s abilities, IRT provides a more detailed view on the information each question provides about a student. It is founded that the probability of a correct response to a test question is a mathematical function of parameters such as a person’s latent traits or abilities and item characteristics (such as difficulty). Figure below shows a typical item response function curve generated by an IRT model. The curve illustrates how an IRT model relates a student’s ability with the probability of answering a question correctly, given that question’s difficulty. IRT models are reliant upon a single measure of ability. They help us better understand how a student’s performance on testing relates to his ability.
